Solutions to Assignments
MCO-03 -
Research Methodology and Statistical Analysis
Question No. 2
(a) What do you understand by the term Correlation? Distinguish between different kinds of correlation with the help of scatter diagrams.
Correlation refers to the statistical relationship between two entities. In other words, it's how two variables move in relation to one another. Correlation can be used for various data sets, as well. In some cases, you might have predicted how things will correlate, while in others, the relationship will be a surprise to you. It's important to understand that correlation does not mean the relationship is causal.
To understand how correlation works, it's important to understand the following terms:
- Positive correlation: A positive correlation would be 1. This means the two variables moved either up or down in the same direction together.
- Negative correlation: A negative correlation is -1. This means the two variables moved in opposite directions.
- Zero or no correlation: A correlation of zero means there is no relationship between the two variables. In other words, as one variable moves one way, the other moved in another unrelated direction.
A scatter diagram is used to examine the relationship between both the axes (X and Y) with one variable. In the graph, if the variables are correlated, then the point drops along a curve or line. A scatter diagram or scatter plot gives an idea of the nature of relationship.
In a scatter correlation diagram, if all the points stretch in one line, then the correlation is perfect and is in unity. However, if the scatter points are widely scattered throughout the line, then the correlation is said to be low. If the scatter points rest near a line or on a line, then the correlation is said to be linear.
Types of Scatter Diagram
You can classify scatter diagrams in many ways; I will discuss the two most popular based on correlation and slope of the trend. These are the most common in project management.
According to the correlation, you can divide scatter diagrams into the following categories:
- Scatter Diagram with No Correlation
- Scatter Diagram with Moderate Correlation
- Scatter Diagram with Strong Correlation
- Scatter Diagram with No Correlation
This diagram is also known as “Scatter Diagram with Zero Degree of Correlation.”

Here, the data point spread is so random that you cannot draw a line through them.
Therefore, you can say that these variables have no correlation.
Scatter Diagram with Moderate Correlation
This diagram is also known as “Scatter Diagram with a Low Degree of Correlation”.

scatter-diagram-with-moderate-correlation
Here, the data points are a little closer and you can see that some kind of relationship exists between these variables.
Scatter Diagram with Strong Correlation
This diagram is also known as “Scatter Diagram with a High Degree of Correlation”.
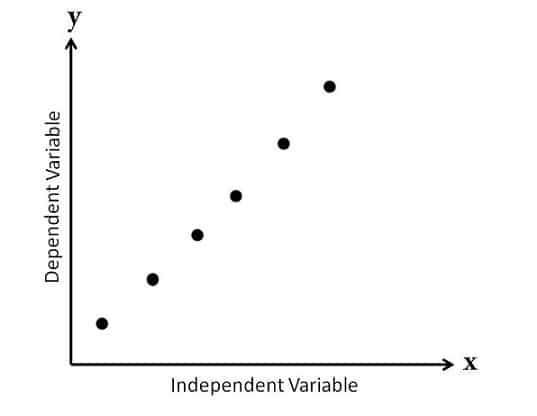
In this diagram, data points are close to each other and you can draw a line by following their pattern.
scatter-diagram-with-strong-correlation
In this case, you say that these variables are closely related.
As discussed earlier, you can categorize the scatter diagram according to the slope, or trend, of the data points:
- Scatter Diagram with Strong Positive Correlation
- Scatter Diagram with Weak Positive Correlation
- Scatter Diagram with Strong Negative Correlation
- Scatter Diagram with Weak Negative Correlation
- Scatter Diagram with Weakest (or no) Correlation
A strong positive correlation means a visible upward trend from left to right; a strong negative correlation means a visible downward trend from left to right. A weak correlation means the trend is less clear. A flat line, from left to right, is the weakest correlation, as it is neither positive nor negative. A scatter diagram with no correlation shows that the independent variable does not affect the dependent variable.
Scatter Diagram with Strong Positive Correlation
scatter-diagram-with-strong-positive-correlation
This diagram is also known as a Scatter Diagram with Positive Slant.
In a positive slant, the correlation is positive, i.e. as the value of X increases, the value of Y will increase. You can say that the slope of a straight line drawn along the data points will go up. The pattern resembles a straight line.
For example, if the weather gets hotter, cold drink sales will go up.
Scatter Diagram with Weak Positive Correlation
scatter-diagram-with-weak-positive-correlation
As the value of X increases, the value of Y also increases, but the pattern does not resemble a straight line.

Scatter Diagram with Strong Negative Correlation
scatter-diagram-with-strong-negative-correlation
This diagram is also known as a Scatter Diagram with a Negative Slant.

In the negative slant, the correlation is negative, i.e. as the value of X increases, the value of Y will decrease. The slope of a straight line drawn along the data points will go down.
For example, if the temperature goes up, sales of winter coats go down.
Scatter Diagram with Weak Negative Correlation
scatter-diagram-with-weak-negative-correlation
As the value of X increases, the value of Y will decrease, but the pattern is not clear.

Scatter Diagram with No Correlation
There isn’t any relationship between the two variables to be seen. It might just be a series of points with no visible trend, or it might be a straight, flat row of points. In either case, the independent variable has no effect on the second variable; it is not dependent.
(b) What do you understand by interpretation of data? Illustrate the types of mistakes which frequently occur in interpretation.
Data interpretation refers to the process of using diverse analytical methods to review data and arrive at relevant conclusions. The interpretation of data helps researchers to categorize, manipulate, and summarize the information in order to answer critical questions.
The importance of data interpretation is evident and this is why it needs to be done properly. Data is very likely to arrive from multiple sources and has a tendency to enter the analysis process with haphazard ordering. Data analysis tends to be extremely subjective. That is to say, the nature and goal of interpretation will vary from business to business, likely correlating to the type of data being analyzed. While there are several different types of processes that are implemented based on individual data nature, the two broadest and most common categories are “quantitative analysis” and “qualitative analysis”.
Yet, before any serious data interpretation inquiry can begin, it should be understood that visual presentations of data findings are irrelevant unless a sound decision is made regarding scales of measurement. Before any serious data analysis can begin, the scale of measurement must be decided for the data as this will have a long-term impact on data interpretation ROI. The varying scales include:
- Nominal Scale: non-numeric categories that cannot be ranked or compared quantitatively. Variables are exclusive and exhaustive.
- Ordinal Scale: exclusive categories that are exclusive and exhaustive but with a logical order. Quality ratings and agreement ratings are examples of ordinal scales (i.e., good, very good, fair, etc., OR agree, strongly agree, disagree, etc.).
- Interval: a measurement scale where data is grouped into categories with orderly and equal distances between the categories. There is always an arbitrary zero point.
- Ratio: contains features of all three.
When performing data analysis, it can be easy to slide into a few traps and end up making mistakes. Diligence is essential, and it’s wise to keep an eye out for the following 7 potential mistakes you can make. These include:
Sampling bias occurs when a non-representative sample is used. For example, a political campaign might sample 1,300 voters only to find out that one political party’s members are dramatically overrepresented in the pool. Sampling bias should be avoided because it can weigh the analysis too far in one particular direction.
Cherry-picking happens when data is stacked to support a particular hypothesis. It’s one of the more intentional problems that appear on this list because there’s always a temptation to give the analysis a nudge in the “right” direction. Not only is cherry-picking unethical, but it may have more serious consequences in fields like public policy, engineering, and health.
Disclosing metrics is a problem because a metric becomes useless once subjects know its value. This ends up creating problems like the habit in the education field of teaching to what’s on standardized tests. A similar problem occurred in the early days of internet search when websites started flooding their content with keywords to game the way pages were ranked.
Overfitting tends to happen during the analysis process. Someone might have a model, for example, and the curve produced by the model seems to be predictive. Unfortunately, the curve is only a curve because the data fits the model. The failure of the model may only become apparent, however, when the model is compared to future observations that aren’t so well-fitted.
Focusing only on the numbers is worrisome because it can have adverse real-world consequences. For example, existing social biases can be fed into models. A company handling lending might produce a model that induces geographic bias by using data derived from biased sources. The numbers may look clean and neat, but the underlying biases can be socially and economically turbulent.
Solution bias can be thought of as the gentler cousin of cherry-picking. With solution bias, a solution might be so cool, interesting or elegant that it’s hard not to fall in love with. Unfortunately, the solution might be wrong, and appropriate levels of scientific and mathematical rigor might not be applied because refuting the solution would just seem disheartening.
Communicating poorly is more problematic than you might expect. Producing analysis is one thing, but conveying findings in an accessible manner to people who didn’t participate in the project is critical. Data scientists need to be comfortable with producing elegant and engaging dashboards, charts and other work products to ensure their findings are well-communicated.
How to Avoid These Problems
Process and diligence are your primary weapons in combating mistakes in data analysis. First, you must have a process in place that emphasizes the importance of getting things right. When you’re creating a data science experiment, there need to be checks in place that will force you to stop and consider things like:
# Where is the data coming from?
# Are there known biases in the data?
# Can you screen the data for problems?
# Who is checking everybody’s work?
# When will results be re-analyzed to verify integrity?
# Are there ethical, social, economic or moral implications that need to be examined more closely before starting?
Diligence is also essential. You should be looking at concerns about whether:
# You have a large and representative enough sample to work with
# There are more rigorous ways to conduct the analysis
# How you’ll make sure analysts are following properly outlined procedures
Tackling a data science project requires sufficient and ample planning. You also have to consider ways to refine your work and to keep improving your processes over time. It takes commitment, but a group with the right culture can do a better job of steering clear of avoidable mistakes.





